- Published on
Data Streams with Lambda
Part 2 of "Requesting Unbounded Streams In Aws"
Table of Contents
- Overview
- The Goal
- Pre-requisites
- Setup
- Infrastructure
- DynamoDB table
- Functions
- Connection Manager
- Event Processor
- Application Code
- Connection Manager
- Establish the Connection and Receive Events
- Write Events To DynamoDB
- Re-Establish the Connection
- Event Processor
- Final Thoughts
- Overlapping Connection Manager Instances
- The Time Between Messages
- Tuning
- Robustness
- We Can. But, Should We?
Overview
The Goal
In this post, we take advantage of the ease of deploying a serverless solution to maintaining an indefinite connection with a client in order to receive and process incoming events. Although designed for short-lived tasks, AWS Lambda will be explored.
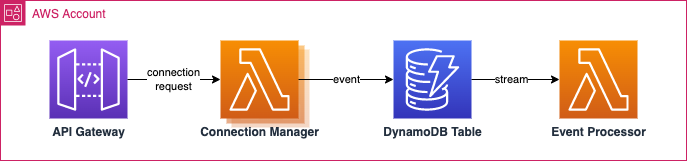
When a request comes into the API Gateway to establish a new stream, the Connection Manager Lambda opens the connection and writes all incoming events to DynamoDB. Each event is then streamed the Event Processor which analyses the payload and applies the business logic for the event.
Pre-requisites
It is assumed that the following are installed and configured:
- Serverless Framework (v3)
- AWS account
Setup
In a new folder create the following files:
.
├── .gitignore
├── env
│ └── env.json
└── serverless.yml
They can be created manually by using the Serverless Framework boilerplate by running sls create --template aws-python3
Environment variables to connect to the stream. This should not be pushed to your version control.
// env/env.json
{
"URL": "example.com/",
"URL_PATH": "path/to/stream",
"KEY": "API_KEY"
}
Ignore the following when pushing to your version control:
# .gitignore
# See https://help.github.com/articles/ignoring-files/ for more about ignoring files.
env/
node_modules/
package-lock.json
# Serverless directories
.serverless
Base infrastructure declaration:
# serverless.yml
service: Lambda-connection-manager
frameworkVersion: '3'
plugins:
- serverless-iam-roles-per-function
provider:
name: aws
runtime: python3.10
region: ${opt:region, 'ap-southeast-2'}
layers:
- arn:aws:Lambda:${self:provider.region}:017000801446:layer:AWSLambdaPowertoolsPythonV2-Arm64:33
iam: # default IAM permissions for all lambdas
role:
statements:
- Effect: "Allow"
Action:
- "s3:ListBucket"
Resource: { "Fn::Join" : ["", ["arn:aws:s3:::", { "Ref" : "ServerlessDeploymentBucket" } ] ] }
- Effect: "Allow"
Action:
- "s3:PutObject"
Resource:
Fn::Join:
- ""
- - "arn:aws:s3:::"
- "Ref" : "ServerlessDeploymentBucket"
- "/*"
- Effect: "Allow"
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
- logs:DescribeLogStreams
Resource: "arn:aws:logs:*:*:*"
functions:
# ...
resources:
# ...
Infrastructure
This section defines the infrastructure of the application which will be used by AWS Cloud Formation to create the following resources:
- API Gateway
- DynamoDB
- Lambda Functions
- Connection Manager
- Event Processor
- DynamoDB Stream
DynamoDB table
- see https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-dynamodb-table.html
- see https://docs.aws.amazon.com/Lambda/latest/dg/invocation-eventfiltering.html
resources:
Resources:
EventTableDbTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: eventTable
BillingMode: PAY_PER_REQUEST
StreamSpecification:
StreamViewType: NEW_IMAGE
AttributeDefinitions:
- AttributeName: PK
AttributeType: S
- AttributeName: SK
AttributeType: S
KeySchema:
- AttributeName: PK
KeyType: HASH
- AttributeName: SK
KeyType: RANGE
Functions
- create the following files
.
├── connection-manager.py
└── event-processor.py
Connection Manager
The connection manager's main goal is to maintain an open connection with the client and ingest any incoming events into our system for processing. Since Lambda has a max running time of 15 minutes, the connection manager will also need to ensure open new connections for long running streams.
The below infrastructure declaration creates an Lambda function which is triggered by an API Gateway REST (v1) endpoint. The REST endpoint will asynchronously trigger the Lambda without waiting for the request to complete (or for the API Gateway request to timeout - max 30 seconds).
The Lambda function is also responsible for adding events to the DynamoDB table for storage
# serverless.yml
# ...
functions:
connection-manager:
name: ${sls:stage}-connection-manager
timeout: 900 # max Lambda timeout
handler: connection-manager.handler
events:
- http: # using http v1 for async
async: true
method: post
path: /connections/{streamId}
request:
parameters:
paths:
streamId: true # required
# environment variables passed to the Lambda
environment:
STREAM_URI: ${file(./env/env.json):URL}
STREAM_KEY: ${file(./env/env.json):KEY}
STREAM_PATH: ${file(./env/env.json):URL_PATH}
STAGE: ${sls:stage}
# additional IAM permissions to be added for the connection manager Lambda
iamRoleStatements: # specific Lambda IAMs
- Effect: "Allow"
Action:
- dynamodb:GetItem
- dynamodb:PutItem
Resource:
Fn::GetAtt:
- EventTableDbTable
- Arn
- Effect: "Allow" # circular dependency when trying to reference the function ARN (could create separately and reference with a depends on?)
Action:
- Lambda:InvokeFunction
Resource: arn:aws:Lambda:${self:provider.region}:${aws:accountId}:function:${sls:stage}-connection-manager
# ...
resources:
# ...
Event Processor
This Lambda is triggered by new events as they are added to the DynamoDB table.
functions:
# ...
event-processor:
name: ${sls:stage}-event-processor
handler: event-processor.handler
events:
- stream:
type: dynamodb
arn:
Fn::GetAtt:
- EventTableDbTable
- StreamArn
filterPatterns:
- eventName: [INSERT] # Only focusing on new events
Application Code
This section is focuses on the application code for each of the Lambdas
Connection Manager
Responsible for maintaining an active connection and writing events to the DynamoDB Table.
Establish the Connection and Receive Events
# connection-manager.py
# ...
@logger.inject_lambda_context(log_event=True)
def handler(event: dict, context: LambdaContext):
stream_id = event['path']['streamId']
url = f'{STREAM_URI}/{STREAM_PATH}/{stream_id}'
headers = {
"Authorization": f"Bearer {STREAM_KEY}"
}
http = urllib3.PoolManager()
try:
# 1. Open connection
resp = http.request(
'GET',
url,
headers=headers,
preload_content=False
)
for chunk in resp.stream(BUFFER_SIZE):
# 2. Write each event to DDB
if chunk and chunk != b'\n': # the client regularly sends new-line characters
write_event(chunk, stream_id)
except Exception as e:
logger.error("An error has occurred during the connection")
logger.error(e)
logger.info("END")
The above code will establish a connection with the client and write incoming events to the DynamoDB table. The connection will remain open for as long as both parties remain open. In this scenario, the maximum time will be dictated by the max running time of our Lambda which can be set to 15 minutes.
Write Events To DynamoDB
In this example, events are unique, but could be duplicated if:
- Multiple streams are open at the same time
- The client sends duplicate messages
- Messages are resent when re-opening a connection
In order to resolve this, the message is hashed and used as the sort key and only added to the table if the message hasn't been added. This behavior is handled by the ConditionExpression.
Add the following function at the end of the file to store each event to DynamoDB.
# connection-manager.py
# ...
def write_event(chunk: bytes, stream_id: str):
SK = hashlib.sha1(chunk).hexdigest() # our messages are unique and could be duplicated
try:
data = chunk.decode('utf-8')
logger.info(data)
ddb_client.put_item(
TableName='eventTable',
Item={
'PK': {
'S': stream_id,
},
'SK': {
'S': SK,
},
'data': {
'S': data
}
},
ConditionExpression='attribute_not_exists(PK) AND attribute_not_exists(SK)' # adds if not duplicate
)
except ClientError as e:
if e.response['Error']['Code']=='ConditionalCheckFailedException': # exception if item exists
pass
else:
logger.error("Error occurred when attempting to store chunk")
logger.error(e)
except Exception as e:
logger.error("An error has occurred when decoding chunk")
logger.error(e)
Re-Establish the Connection
The main flaw with the above approach is that the connection will be automatically closed once the Lambda execution time limit is reached. The abrupt end could occur during the processing of an event or any other function and the logger at the end of the handler (logger.info("END")) will never be written.
In order to overcome this, the function needs to keep a track of it's processing time and decide when to end gracefully. And, just before ending, the function needs to invoke a new instance of the connection manager.
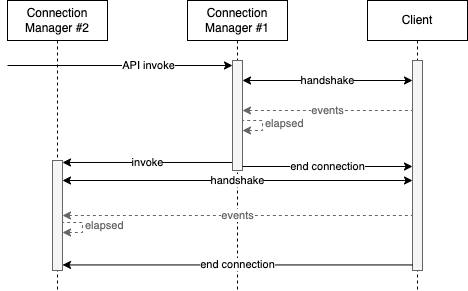
To achieve this, the Lambda needs to regularly check the total elapsed time. Which will be done after each message has been received. It is important to note, that the client used in this example sends a message every few seconds whether updates exist or not.
Update the handler function with the below:
# connection-manager.py
import json
import os
import urllib3
import boto3
import hashlib
from datetime import datetime
from aws_lambda_powertools import Logger
from aws_lambda_powertools.utilities.typing import LambdaContext
from botocore.exceptions import ClientError
logger = Logger()
ddb_client = boto3.client('dynamodb')
lambda_client = boto3.client('lambda')
STREAM_URI = os.environ['STREAM_URI']
STREAM_PATH = os.environ['STREAM_PATH']
STREAM_KEY = os.environ['STREAM_KEY']
STAGE = os.environ['STAGE']
MAX_CONNECTION_TIME = 840 # connect to server for 14 minutes
TIMEOUT = 30 # time between events
BUFFER_SIZE = 1024
@logger.inject_lambda_context(log_event=True)
def handler(event: dict, context: LambdaContext):
logger.info("START")
start = int(datetime.now().timestamp())
invocation = event['path'].get('invocation') # used in logging to identify the lambda instance
if not invocation:
invocation = 0
stream_id = event['path']['streamId']
url = f'{STREAM_URI}/{STREAM_PATH}/{stream_id}'
headers = {
"Authorization": f"Bearer {STREAM_KEY}"
}
timeout = urllib3.Timeout(total=TIMEOUT) # refers to the total timeout between events
http = urllib3.PoolManager(timeout=timeout)
try:
# 1. Open Connection
resp = http.request(
'GET',
url,
headers=headers,
preload_content=False
)
for chunk in resp.stream(BUFFER_SIZE):
# 2. Write each event to DDB
if chunk and chunk != b'\n':
write_event(chunk, stream_id)
# 3. After max connection time, spin up a new connection manager instance and close connection in this instance
now = int(datetime.now().timestamp())
elapsed_seconds = now - start
if elapsed_seconds >= MAX_CONNECTION_TIME:
logger.info("Max connection time exceeded...attempting to establish a new connection manager")
reopen_connection(stream_id, invocation)
# Wait here before ending the connection?
break
except Exception as e:
logger.error("An error has occurred during the connection")
logger.error(e)
logger.info("END")
The function to re-establish a connection is below:
# connection-manager.py
def reopen_connection(stream_id: str, invocation: int):
try:
payload = {
"path": {
"streamId": stream_id,
"invocation": invocation + 1
}
}
response = lambda_client.invoke(
FunctionName=f'{STAGE}-connection-manager',
InvocationType='Event',
Payload=json.dumps(payload)
)
if response["StatusCode"] < 300:
logger.info("New connection manager established")
else:
logger.error("Invoke request failed")
except Exception as e:
logger.error("Error when attempting to invoke connection manager")
logger.error(e)
Event Processor
This function is out of scope for this series as it will largely depend on the incoming events and business requirements. The Event Processor is in charge of handling each event as it is streamed from DynamoDB.
from aws_lambda_powertools import Logger
logger = Logger()
@logger.inject_lambda_context(log_event=True)
def handler(event, context):
logger.info("START")
for record in event['Records']:
logger.info(record)
streamId = record['dynamodb']['Keys']['PK']['S']
data = record['dynamodb']['NewImage']['data']['S']
# ...
Final Thoughts
Although we have demonstrated a workflow which can receive events for long running streams beyond the 15 minute window, this is largely dependant on the client. Some considerations are:
Overlapping Connection Manager Instances
Once a Lambda is triggered by either the API Gateway call or via an invocation by another lambda, there will be some latency before an active connection is established. Consider the normal start time of the application and the handshake between the Lambda and Client. In addition other factors such as cold start times may be a factor (especially for the first call). In our example the existing connection is closed when the new connection is established. This may differ depending on the client.
The Time Between Messages
Since the client sends messages every few seconds, the function can check the elapsed time regularly. If the connection was idle for minutes or hours between events some other mechanism to keep track of the elapsed time would be required.
Additionally, any timeout for the PoolManager should be long enough to ensure that the connection isn't closing while awaiting updates.
Tuning
What is the max buffer size for each chunk? What are the optimal memory settings for Lambda?
Robustness
The above example only attempts to reestablish a new connection if the max connection time has elapsed. However, there could be other reasons that the connection may end prematurely, such as:
- Error from the client
- Unexpected event format or size
Is there a signal from the client to signify the end of a stream? What is the expected frequency of the incoming events, and can we determine an issue from the time time in between events?
We Can. But, Should We?
Just because it is possible (and even simple) to handle in AWS Lambda, should we? Other than cost, the 'hacky' functionality contravenes Lambdas intended purpose and results in an awkward mix of with infrastructure logic and application code.