- Published on
Orchestrating Streams With Step Functions
Part 3 of "Requesting Unbounded Streams In Aws"
Table of Contents
Overview
Part 2 explored how Lambda could be used to manage a long running stream beyond Lambdas 15 minute hard limit. This was achieved by invoking another Lambda instance of the connection manager as the execution limit approached. A new lambda would be spun up to handle incoming events, closing the connection to the initial instance.
This process, although successful, ends up being an awkward mix of the function code as well as the infrastructure orchestration.
The Goal
This post explores if separation between the function code and the instance orchestration can be achieved with AWS Step Functions.
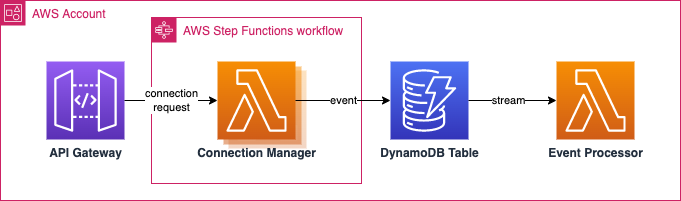
Pre-requisites
This follows on from part 2, so it is assumed that the following are installed and configured:
- Serverless Framework (v3)
- AWS account
Connection Manager
The same code from Part 2 can be used after removing all time-keeping, retry, and connection termination logic from the Lambda. The expected behavior will be:
- Once invoked, establish a stream to the client
- Receive incoming events and write them to the DynamoDB table
- Once the Lambda execution limit is reached, the Lambda will terminate, in-turn closing the connection (less than gracefully)
- Additional logic is needed to determine the state of stream if closed before the execution limit is reached (more on this later)
Ideally, we would aim for something similar to the below stripped function, with all fo the infrastructure orchestration logic removed:
# connection-manager.py
import json
import os
import urllib3
import boto3
import hashlib
from datetime import datetime
from aws_lambda_powertools import Logger
from aws_lambda_powertools.utilities.typing import LambdaContext
from botocore.exceptions import ClientError
logger = Logger()
ddb_client = boto3.client('dynamodb')
lambda_client = boto3.client('lambda')
STREAM_URI = os.environ['STREAM_URI']
STREAM_PATH = os.environ['STREAM_PATH']
STREAM_KEY = os.environ['STREAM_KEY']
STAGE = os.environ['STAGE']
TIMEOUT = 10
MAX_CONNECTION_TIME = 30
BUFFER_SIZE = 1024
@logger.inject_lambda_context(log_event=True)
def handler(event: dict, context: LambdaContext):
logger.info("START")
stream_id = event['path']['streamId']
url = f'{STREAM_URI}/{STREAM_PATH}/{stream_id}'
headers = {
"Authorization": f"Bearer {STREAM_KEY}"
}
timeout = urllib3.Timeout(read=TIMEOUT)
http = urllib3.PoolManager(timeout=timeout)
try:
# 1. Open Connection
resp = http.request(
'GET',
url,
headers=headers,
preload_content=False
)
for chunk in resp.stream(BUFFER_SIZE):
# 2. Write each event to DDB
if chunk and chunk != b'\n':
write_event(chunk, stream_id)
except Exception as e:
logger.error("An error has occurred during the connection")
logger.error(e)
logger.info("END")
def write_event(chunk: bytes, stream_id: str):
SK = hashlib.sha1(chunk).hexdigest() # our messages are unique and could be duplicated
try:
data = chunk.decode('utf-8')
logger.info(data)
ddb_client.put_item(
TableName='eventTable',
Item={
'PK': {
'S': stream_id,
},
'SK': {
'S': SK,
},
'data': {
'S': data
}
},
ConditionExpression='attribute_not_exists(PK) AND attribute_not_exists(SK)'
)
except ClientError as e:
if e.response['Error']['Code']=='ConditionalCheckFailedException':
# Item exists
pass
else:
logger.error("Error occurred when attempting to store chunk")
logger.error(e)
except Exception as e:
logger.error("An error has occurred when decoding chunk")
logger.error(e)
Retry on Timeout
This example allows the Lambda to connect to the server and maintain the connection for as long as possible. Once the connection is closed, the retry logic is used to trigger a new instance of the Connection manager until a success state is reached. 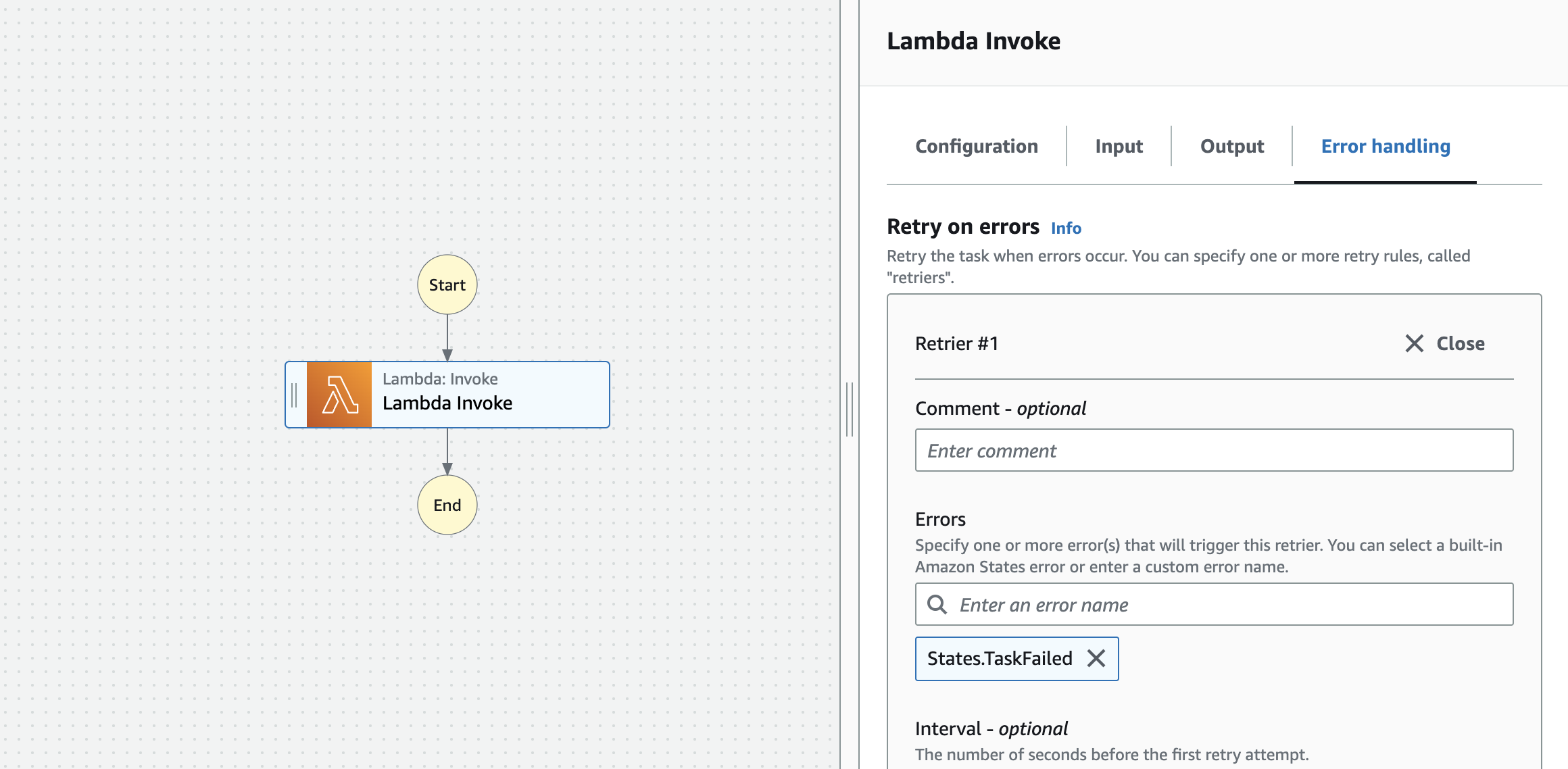
Once the Lambdas execution limit has been reached, the process is terminated and the function is unable to reach a resolution. 
This would be considered a failure state, initiating the retry. To test, the Lambda execution time is set for 45 seconds. The task list below demonstrates how the process is restarted each time the Lambda times out. 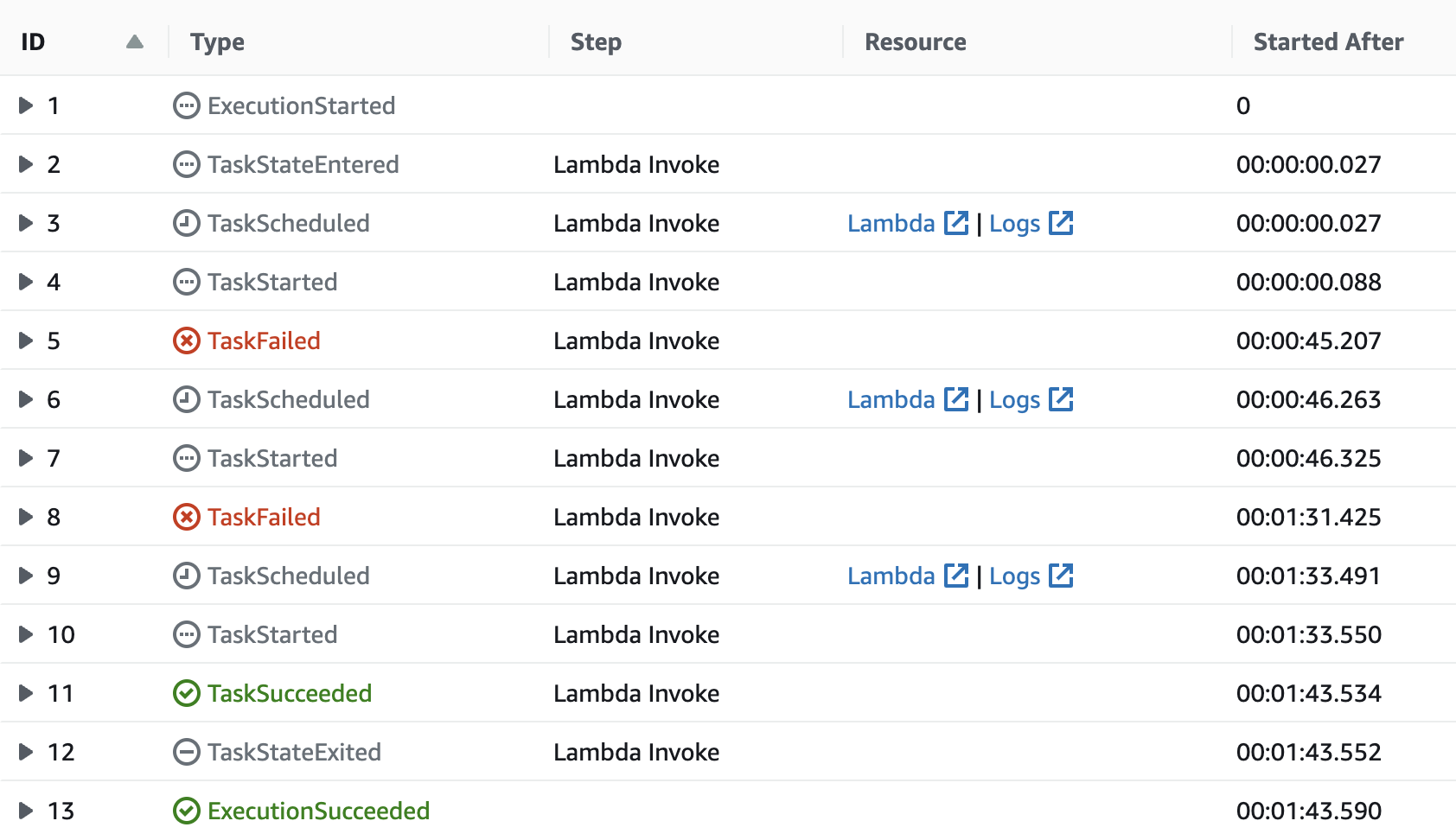
This outcome is less than desirable as there is a good 1 - 2 second delay between one Lambda's termination and the next's. There is also a delay between the Lambda's start time and a successful connection to the client.
Staggered Start
An attempt to reduce/eliminate the delay between stream instances would be to implement some staggered functionality, with one instance starting before the next instance begins. This would be similar to previous part, where the new stream is invoked while the connection is still running.
In this example attempts, we use Step Functions to orchestrate 2 staggered branching Lambda functions, ensuring that the second branch would start just before the first instance terminates. Ideally, the left branch would either cause no action on timeout and the right branch would restart the iteration after the wait condition opening another instance of the connection manager before the first closed.
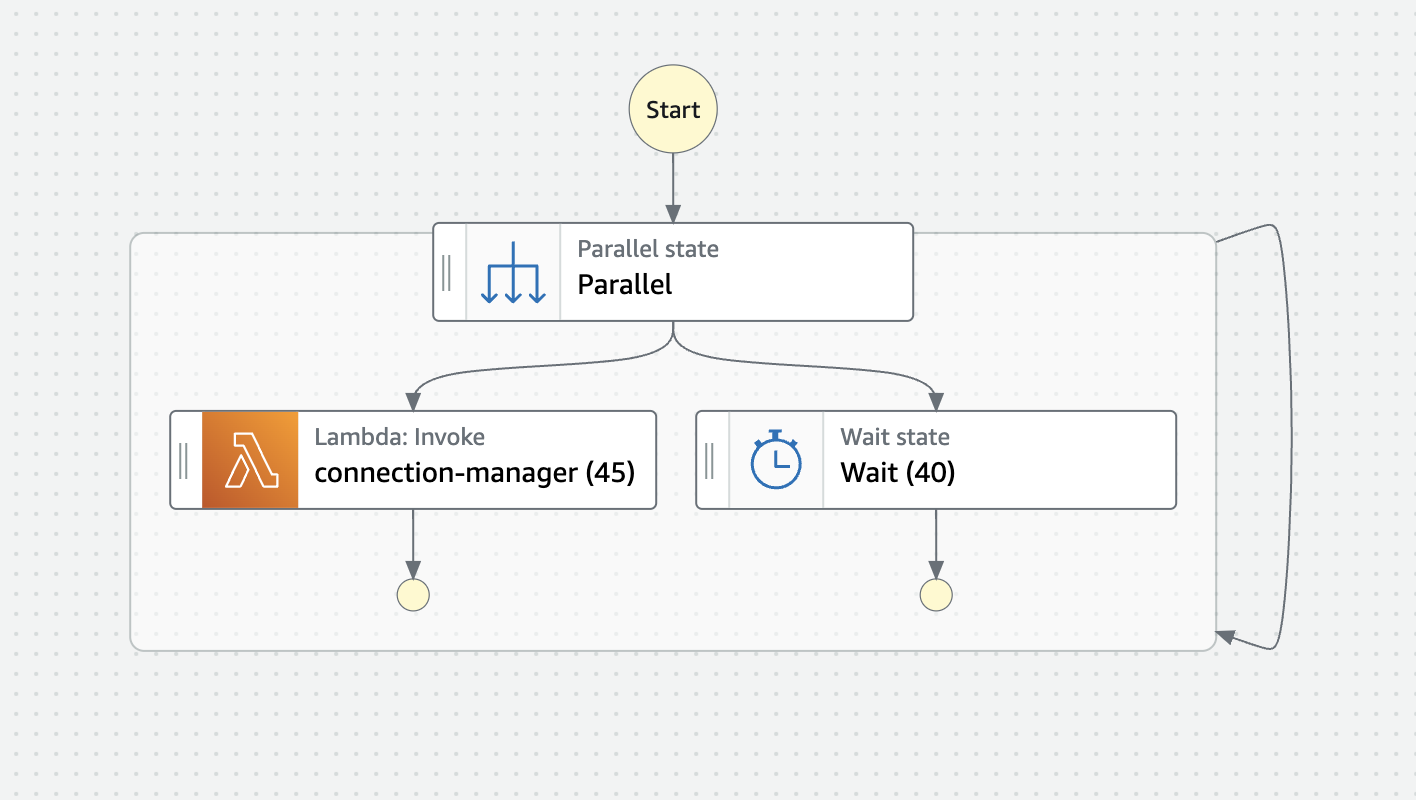
Due to the nature of how Step Functions work, all parallel branches need to end before the next state can be started, and processes within a parallel process' scope cannot start a process outside of this scope. The above would result in the first Lambda running for it's max time (45 seconds in the example) while the second branch waits for 40 seconds. The second branch would then sit idle waiting for the the first branch to complete. Once both branches are complete, the next iteration will start resulting in a gap between instances.
In addition, the error states will need to be appropriately handled as any failed branches result in the parallel process failure, terminating the state machine.
Another option could be to maintain two independent branches running concurrently throughout the duration of the stream. The first branch will start waiting while the other branch triggers the connection manager immediately. The first branch is set to trigger a new instance of the connection manager just before the instance in the second branch terminates. Both branches are configured trigger the wait flow in the event of a timeout error, or proceed to the end of the branch on successful completion of the stream.
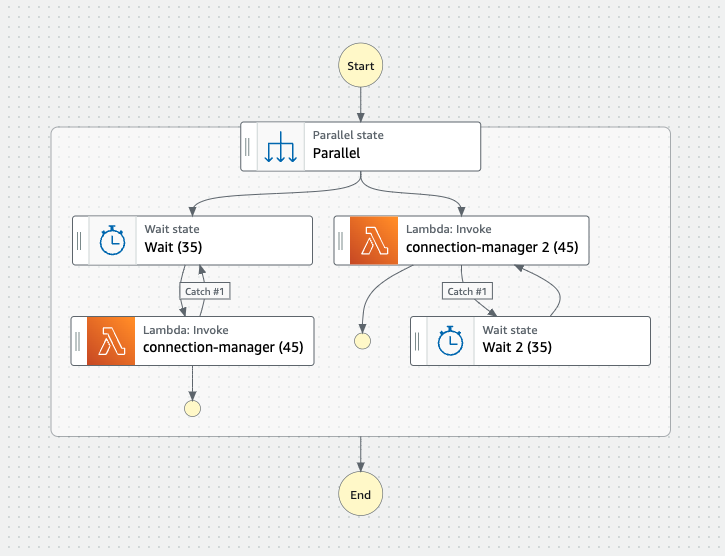
The main issues with this approach is the the state of each Lambda. Once a connection is started, the client immediately kills the old connection. This results in a success scenario from the first Lambda, stopping its retry loop, leaving one branch to run until the lambda timeout and wait 35 seconds before starting again.
To resolve this, additional logic needs to be added to:
- Force an error when the connection was closed before the stream is complete
- Handle the stream ended state both during a connection and when trying to establish a new connection. Handling this may differ from client to client
def handler(event: dict, context: LambdaContext):
logger.info("START")
# ...
stream_ended = False # <-- keep info about stream
try:
resp = http.request(
'GET',
url,
headers=headers,
preload_content=False
)
for chunk in resp.stream(BUFFER_SIZE):
# Check if stream has ended
if end_signal_received(chunk):
stream_ended = True
break
if chunk and chunk != b'\n':
write_event(chunk, stream_id)
except Exception as e:
logger.error("An error has occurred during the connection")
logger.error(e)
if not stream_ended:
raise Exception("Stream not closed") # <-- force an error for the retry
logger.info("END")
def end_signal_received(chunk):
# Extract the state of the stream from the chunk
pass
After running, here is an example of the processing times using shorter lambda and wait times.
| Time | Stream A | Stream B |
|---|---|---|
| 0 | ||
| 00:00:00.025 | ||
| 00:00:00.025 | Wait (35) start | connection-manager 2 (45) start |
| 00:00:35.080 | Wait (35) end | Duration: 00:00:37.037 |
| 00:00:35.136 | connection-manager (45) start | |
| 00:00:36.718 | connection-manager 2 (45) end | |
| 00:00:36.718 | Duration: 00:00:38.038 | Wait 2 (35) start |
| 00:01:11.782 | Wait 2 (35) end | |
| 00:01:11.845 | connection-manager 2 (45) start | |
| 00:01:12.791 | connection-manager (45) end | |
| 00:01:12.791 | Wait (35) start | Duration: 00:00:37.037 |
| 00:01:47.851 | Wait (35) end | |
| 00:01:48.016 | connection-manager (45) start | |
| 00:01:48.928 | connection-manager 2 (45) end | |
| 00:01:48.928 | Duration: 00:00:37.037 | Wait 2 (35) start |
| 00:02:23.990 | Wait 2 (35) end | |
| 00:02:24.049 | connection-manager 2 (45) start | |
| 00:02:24.974 | connection-manager (45) end |
Infrastructure
There arnt't many changes required for this approach. The main changes are:
- Remove all of the invocation logic from the connection manager (outlined above)
- Define the Step Function
- Set API GW to Trigger Step function instead of Lambda (configured within step function declaration)
- Minor updates
Step Function
Since the tests were created in the AWS console, the definition can be directly copied. Here is an example output:
{
"Comment": "A description of my state machine",
"StartAt": "Parallel",
"States": {
"Parallel": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Wait (35)",
"States": {
"Wait (35)": {
"Type": "Wait",
"Seconds": 35,
"Next": "connection-manager (45)"
},
"connection-manager (45)": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-southeast-2:123456789:function:dev-connection-manager:$LATEST"
},
"End": true,
"Catch": [
{
"ErrorEquals": [
"States.TaskFailed"
],
"Next": "Wait (35)",
"ResultPath": null
}
],
"ResultPath": null
}
}
},
{
"StartAt": "connection-manager 2 (45)",
"States": {
"connection-manager 2 (45)": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:ap-southeast-2:123456789:function:dev-connection-manager:$LATEST"
},
"ResultPath": null,
"Catch": [
{
"ErrorEquals": [
"States.TaskFailed"
],
"Next": "Wait 2 (35)",
"ResultPath": null
}
],
"End": true
},
"Wait 2 (35)": {
"Type": "Wait",
"Seconds": 35,
"Next": "connection-manager 2 (45)"
}
}
}
],
"ResultPath": null,
"End": true
}
}
}
Install the serverless-step-functions plugin
$ npm install --save-dev serverless-step-functions
Using an online JSON to YAML converter, we converted the above JSON and added it to the state machine declaration:
# serverless.yml
stepFunctions:
stateMachines:
state-machine-trigger:
name: connectionManagerStateMachine
definition:
Comment: A description of my state machine
StartAt: Parallel
States:
Parallel:
Type: Parallel
Branches:
- StartAt: Wait
States:
Wait:
Type: Wait
Seconds: 35 # <--- update wait time
Next: connection-manager
connection-manager:
Type: Task
Resource: arn:aws:states:::lambda:invoke
Parameters:
Payload.$: "$"
FunctionName: arn:aws:lambda:ap-southeast-2:${aws:accountId}:function:${sls:stage}-connection-manager
End: true
Catch:
- ErrorEquals:
- States.TaskFailed
Next: Wait
ResultPath:
ResultPath:
- StartAt: connection-manager 2
States:
connection-manager 2:
Type: Task
Resource: arn:aws:states:::lambda:invoke
Parameters:
Payload.$: "$"
FunctionName: arn:aws:lambda:ap-southeast-2:${aws:accountId}:function:${sls:stage}-connection-manager
ResultPath:
Catch:
- ErrorEquals:
- States.TaskFailed
Next: Wait 2
ResultPath:
End: true
Wait 2:
Type: Wait
Seconds: 35 # <--- update wait time
Next: connection-manager 2
ResultPath:
End: true
API Gateway Trigger
In Part 2, the API Gateway triggered the connection manager Lambda directly. This needs to be amended to kick of the state machine instead.
Remove the trigger from the Lambda function
# serverless.yml
# ...
functions:
connection-manager: # had to change due to character constraint
name: ${sls:stage}-connection-manager
timeout: 45
handler: connection-manager.handler
# events:
# - http: # using http v1 for async
# async: true
# method: post
# path: /connections/{streamId}
# request:
# parameters:
# paths:
# streamId: true # enforcing true
environment:
STREAM_URI: ${file(./env/env.json):URL}
STREAM_KEY: ${file(./env/env.json):KEY}
STREAM_PATH: ${file(./env/env.json):URL_PATH}
STAGE: ${sls:stage}
iamRoleStatements: # specific lambda IAMs
- Effect: "Allow"
Action:
- dynamodb:GetItem
- dynamodb:PutItem
Resource:
Fn::GetAtt:
- EventTableDbTable
- Arn
# - Effect: "Allow" # no longer need permission to invoke the connection manager
# Action:
# - lambda:InvokeFunction
# Resource: arn:aws:lambda:${self:provider.region}:${aws:accountId}:function:${sls:stage}-connection-manager
Add the trigger to the state machine
# serverless.yml
# ...
stepFunctions:
stateMachines:
state-machine-trigger:
events:
- http:
path: /connections/{streamId}
method: post
request:
parameters:
paths:
streamId: true # enforcing true
template: lambda_proxy # <-- passes the lambda context to pass request into the step function
name: connectionManagerStateMachine
definition:
Comment: A description of my state machine
# ...
This infrastructure calls for a slight change to the Lambda function as the streamId was being passed in via event['path']['streamId']. However, this is now passed in via event['pathParameters']['streamId']. Update all instances of this in the serverless.yml.
Conclusion
This experiment shows how it is possible to use AWS Step Functions to maintain long running connections well beyond the lifespan of Lambda. All of of the orchestration logic is handled outside of the Lambda functions with minor code changes. This separation has come at a considerable monitory cost by paying for both Lambda and AWS Step Functions.